Help: 部分一致検索とあいまい検索
ST PANGAEAでは、一部の検索項目で部分一致検索とあいまい検索を利用できます。なお、これらの検索機能では、英数字の半角/全角/大文字/小文字の違いや、異体字などの違いは吸収され、おなじ文字として識別されます。
部分一致検索
部分一致検索では、次のような検索式をサポートしています。
| 種類 | 検索式 | 例 |
|---|---|---|
| AND検索 | キーワード同士をスペースで区切る |
人工知能 機械学習 →「人工知能」と「機械学習」の両方を含む文書を検索 |
| 連語の検索 | ダブルクォートを用いる |
”machine learning” →「machine learning」という連語を含む文書を検索 |
| OR検索 | 「OR」オペレータを利用 |
”machine learning” OR 機械学習 →「machine learning」または「機械学習」のいずれかを含む文書を検索 |
| NOT検索 | 半角のマイナス「-」をキーワードの先頭につける |
機械学習 -人工知能 →「機械学習」を含み、「人工知能」を含まない文書を検索 (NOT条件単独での検索は不可。必ず他の条件と組み合わせる必要がある。) |
| 優先順位の指定 | 半角括弧を利用 |
人工知能 (”machine learning” OR 機械学習) →「人工知能」と「machine learning」、または「人工知能」と「機械学習」 |
あいまい検索
「あいまい検索」を選択して検索すると、分散表現によるあいまい検索が利用できます。
分散表現(Word Embedding,単語の埋め込み)とは、単語を多次元の実数値のベクトルで表現する技術です。 同じような文脈で使われる単語が近くに配置されるため、意味的に近い単語ほど距離も近いと期待できます。 したがって、分散表現を用いて単語をベクトルで表現することで、(意味もある程度踏まえたように見える形で)単語間の距離を数値的に計算することができます。
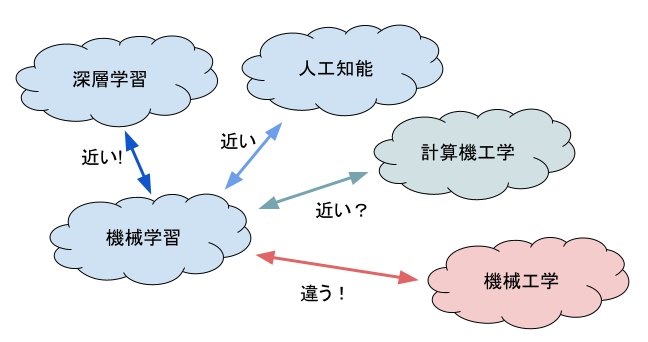
本システムのあいまい検索では、収録されている文書や検索フォームから入力された文字列などの文章について、形態素解析器を用いて文章中の単語を抽出し、各単語のベクトルを足し合わせて単位ベクトル化したものを、文章のベクトルとして利用しています。
文章間の距離には、文章ベクトルのユークリッド距離を用います。文章ベクトルはあらかじめ単位ベクトル化されているため、2つの文章間の距離は0~2までの実数値をとります。 この距離が0に近いほど類似度が高く、2に近いほど類似度が遠いことを意味します。
検索語と関連度の高いデータがデータベースに含まれていない場合、あいまい検索の精度は下がります。あいまい検索の検索結果が不十分な場合は、他の十分な精度の結果が得られる検索語と関連度(距離)を比較してみたり、部分一致検索で関連度の高いデータがデータベースに含まれているかどうか確認してみてください。
単語ベクトルのデータは、日本の研究.com から提供された、 分野推定モデル で利用している単語ベース分散表現モデルを利用しました。
Help 目次
ST PANGAEAとは?
収録データと検索機能について
- NISTEP注目科学技術
- 科研費研究課題
- 部分一致検索とあいまい検索